Designing Classic’s memory allocator
Memory
Before even starting to design the memory allocator itself, I had to decide where the heap (memory zone managed by the allocator) will reside in memory.
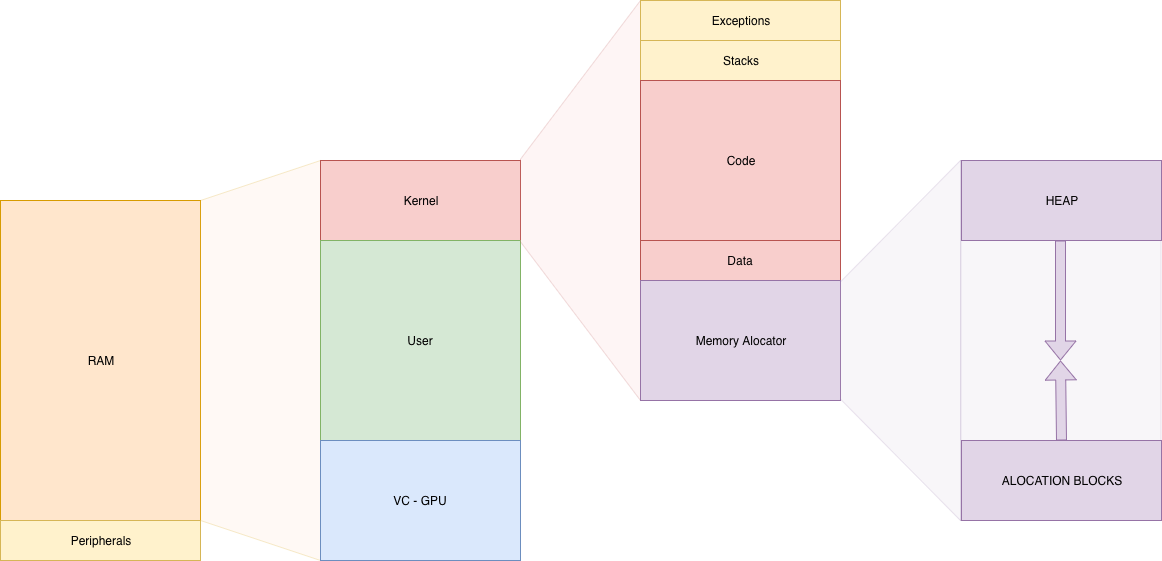
As you can see the kernel has its own heap and memory allocator. The user space uses a separate but similar allocator (for security purposes) and the heap is loaded at the end of the initial virtual memory allocated to a task.
When designing a memory allocator you will have to make all kinds of decision depending on why and where you need malloc. In my case I wanted a general purpose memory allocator.
Structure
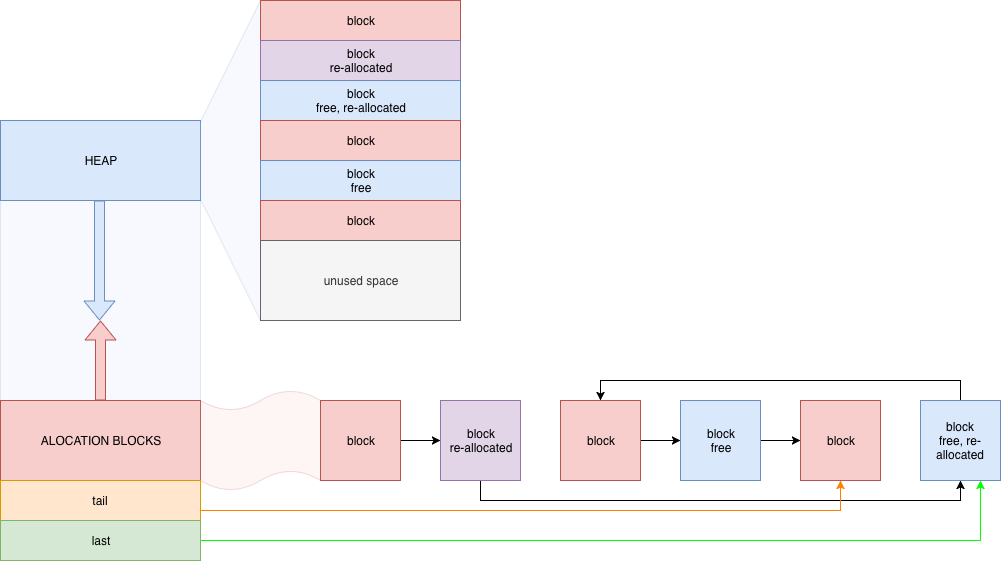
First design choice I had to make was how to store the memory blocks, distinguish free blocks from allocated blocks.
typedef struct mem_block {
u32 size;
void* addr;
struct mem_block* next;
} mem_block;
The structure above was used to represent memory blocks of a given size which started on the stack at addr and pointed to the next block next.
This design formed a linked list which could be easily tracked using:
static mem_block* _KERNEL_ALOC = (void*)0x000FFFFF;
mem_block* _KERNEL_ALOC_LAST;
mem_block* _KERNEL_ALOC_TAIL;
Here the _KERNEL_ALOC_LAST pointer is the last memory block in physical memory and _KERNEL_ALOC_TAIL pointer is the last memory block in the linked list of memory blocks.
_KERNEL_ALOC_LAST is used to free up fragmented memory in the structure of the memory allocator.
Alignment
A rule/trade-off I employed was 16 word aligned memory allocations, meaning that all addresses within the heap would look like 0xFFFFFFF0 allowing the first 4 bits to be used as flags. Bit 0, represents if the block is allocated (0) or free (1).
While speed is a very important aspect when dealing with memory operations we also want to optimise the memory we allocate and NEVER lose portions of memories (memory leaks) especially at the very foundation of the memory allocator.
When looking to allocate a block of memory, first the input size must be validated. What happens when a users calls malloc(1), are we seriously going to allocate a 1 byte block? Of course not, we will allocate a block of MIN_SIZE (in my case 64 bytes or 16 words) and the programmer is free to use a single byte or all 64. Now what happens when the user makes a call for malloc(1073741824)? Do we just give up 1GB of memory to a single program? Obviously not, we are going to allocate a MAX_SIZE block and now comes another design decision related to actual physical memory allocated, and we have two main approaches: lazy or eager.
Lazy
We “tell” the user he can have his huge amount of memory but we don’t allocate all of the physical pages until the user actually uses the requested memory address. Think of it like Cloud Storage services, they might offer you 50GB but that space is not reserved for you until you actually use it, because not all users will fill 50GB of data.
Eager
Actually allocate the requested memory and pray that you didn’t just starve the entire system or that you have plenty of swap space.
Speed
While most tasks will handle a O(n) style iterative algorithm there are ways to speed up memory allocation. One is creating another linked of free blocks and adding another next pointer to the next free block. This greatly increases allocation time to O(1) but requires additional memory to store the pointers
Another speed/memory trade-off is related to contiguous free memory blocks. When allocating 256 bytes of memory, it is possible to have a free block of 64 bytes and another neighbouring free block of 192 bytes. A nice design choice is to search all contiguous free blocks until their sizes add up to the requested allocation or more and then perform a merge within the allocator structure.
Another speed/memory trade-off is what happens when you want to allocate let’s say 64 bytes, and the first free block is 1024 bytes, but somewhere down the list a 64 byte free block can be found. Do we always search for the best matching smallest block? Do we fragment memory? Or create a score/heuristic to decide when to be greedy and when to optimise memory.
If a specific program requires absolute speed and wishes to bypass all other checks, I like to implement a fast malloc call, falloc, that spawns another allocation block at the very end of the list ignoring any and all memory optimisations.
Free
Freeing up blocks can be slow at times, because you have to search for the right address of the block, which without any sort of mapping will be O(n). What you can do to optimise speed is not actually free up the memory at the time of the free call instead you can save up a batch of free request and perform them in one iteration. Another optimisation is performing memory frees when as a daemon task whenever the scheduler decides it has the resources for it.
These two options delay memory frees and could cause a lot of memory to stagnate until the requests are truly processed.